✔️ 50k Image caption generated by GPT-4o
✔️ 2k Video caption generated by GPT-4o
[TBD] Voice caption generated by GPT-4o
[TBD] More image/video caption/QA generated by GPT-4o
In the realm of large multimodal models, achieving efficient modality alignment is a critical challenge, often hindered by the scarcity of high-quality image-text, video-text data and audio-text data. To address this issue, we introduce the ShareGPT-4o dataset, a groundbreaking large-scale resource that we plan to open-source with 200K meticulously annotated images, 10K videos with highly descriptive captions, and 10K audio files with detailed descriptions. This dataset sets a new standard in diversity and informational richness, encompassing extensive world knowledge, detailed object properties, spatial relationships, and aesthetic evaluations. ShareGPT-4o leverages the advanced multimodal capabilities of GPT-4o, ensuring each data point is carefully curated for maximum utility. By releasing this dataset, we aim to provide a pivotal resource that will significantly advance the progress of the LMM community, facilitating more effective modality alignment and enhancing the overall performance of multimodal models.
| Dataset Name | Domain | Visible | Captioned by | Samples |
|---|---|---|---|---|
| COCO-Caption | Image | ✔︎ | Human | 118K |
| BLIP-LCS | Image | ✔︎ | BLIP | 558K |
| LLaVA-23K | Image | ✗ | GPT4 | 23K |
| ShareGPT4V | Image | ✔︎ | GPT4-Vision | 100K |
| ShareGPT-4o | Image, Video, Audio(coming soon) | ✔︎ | GPT-4o | 200k+10k+10k |
Comparison of widely-used caption datasets and ShareGPT-4o.
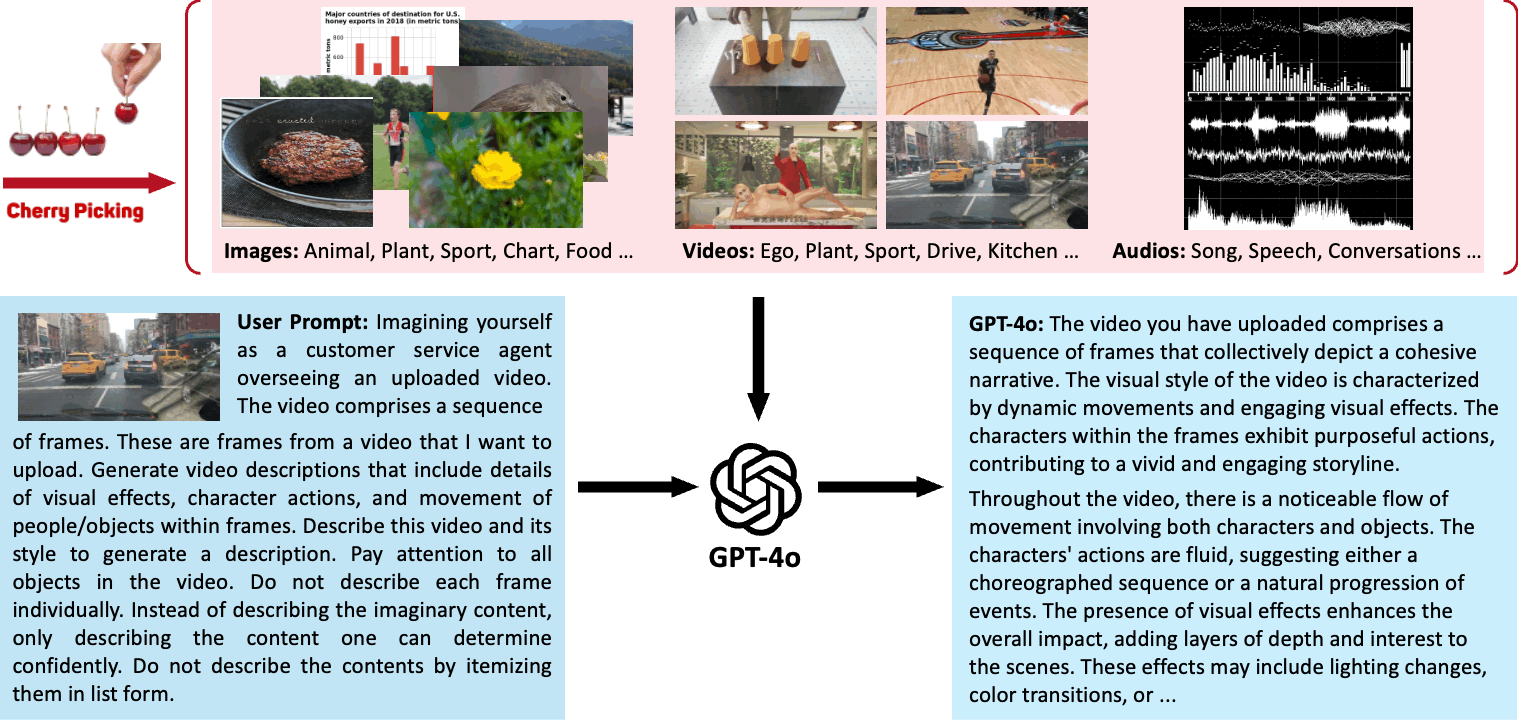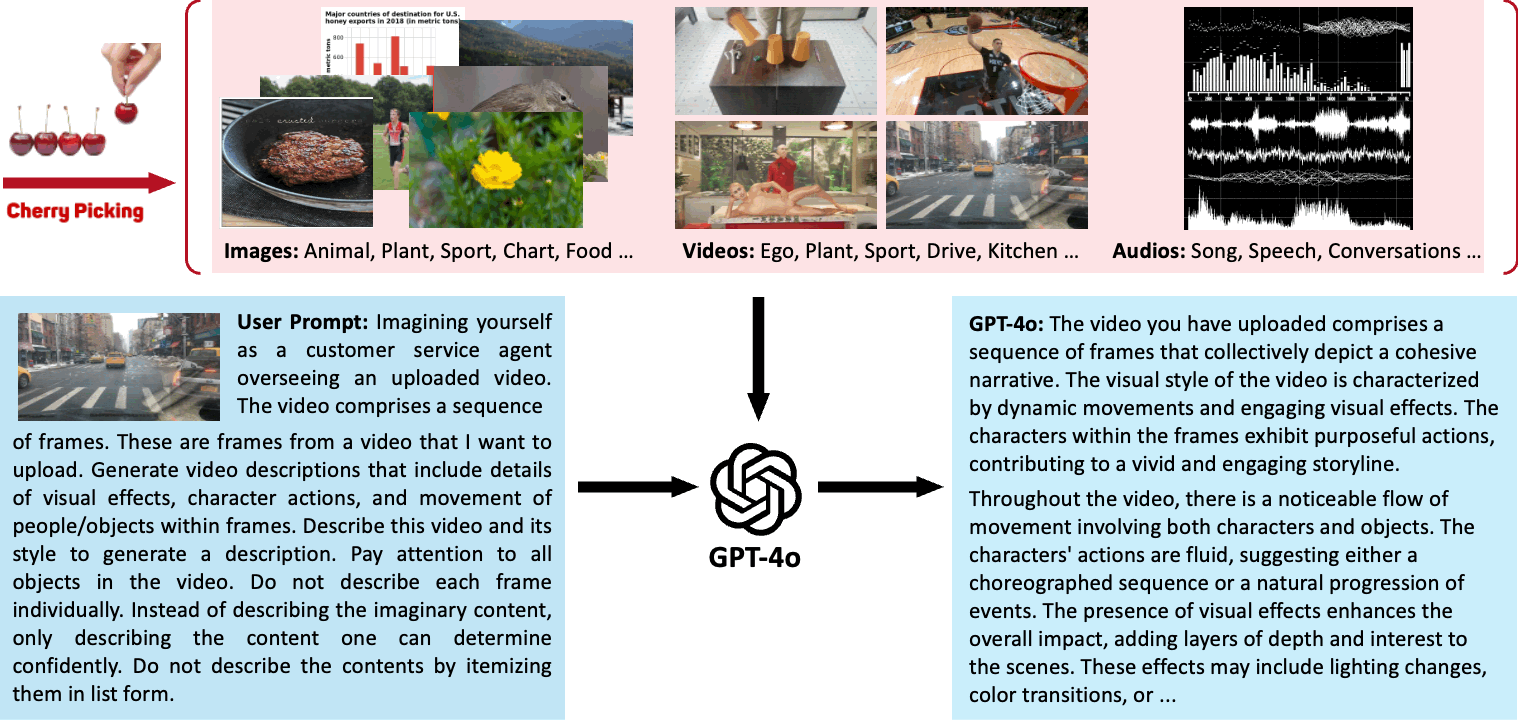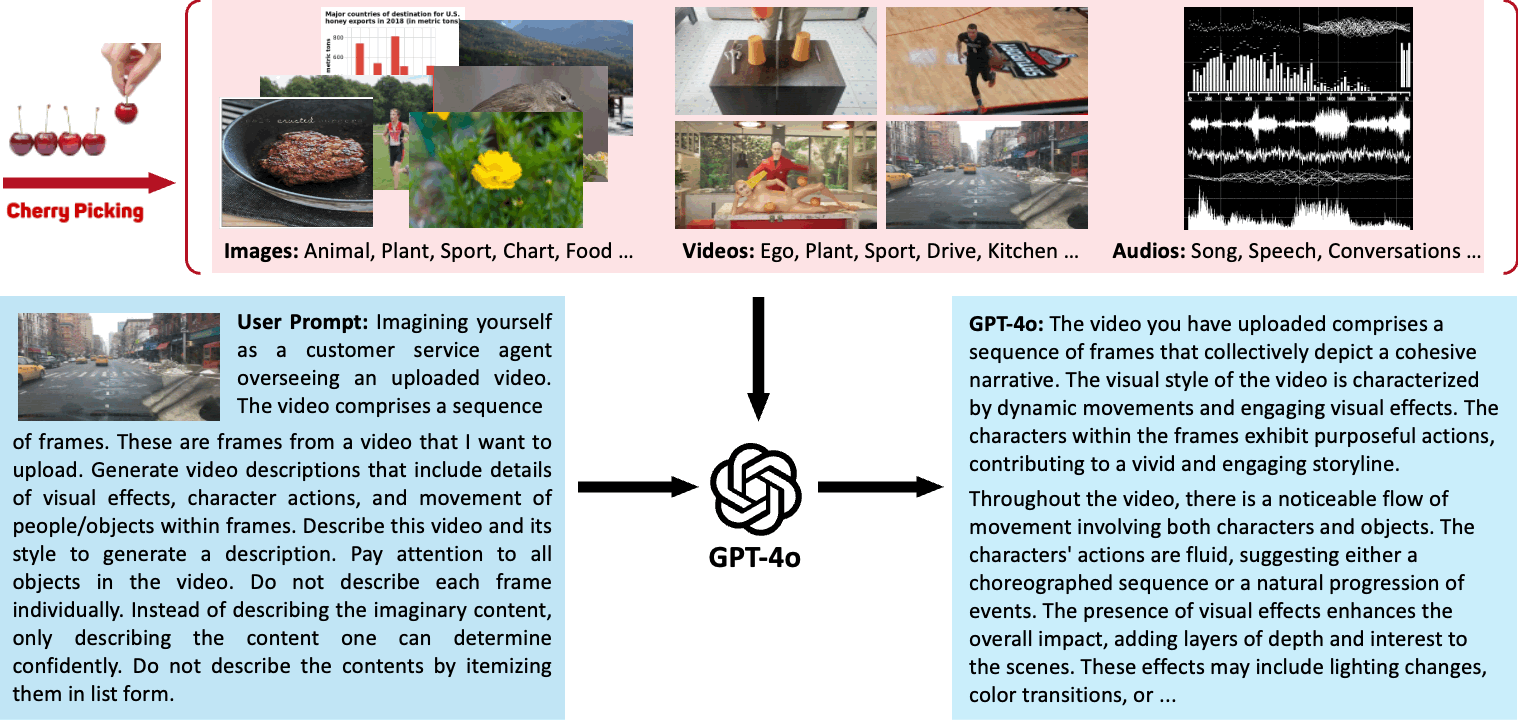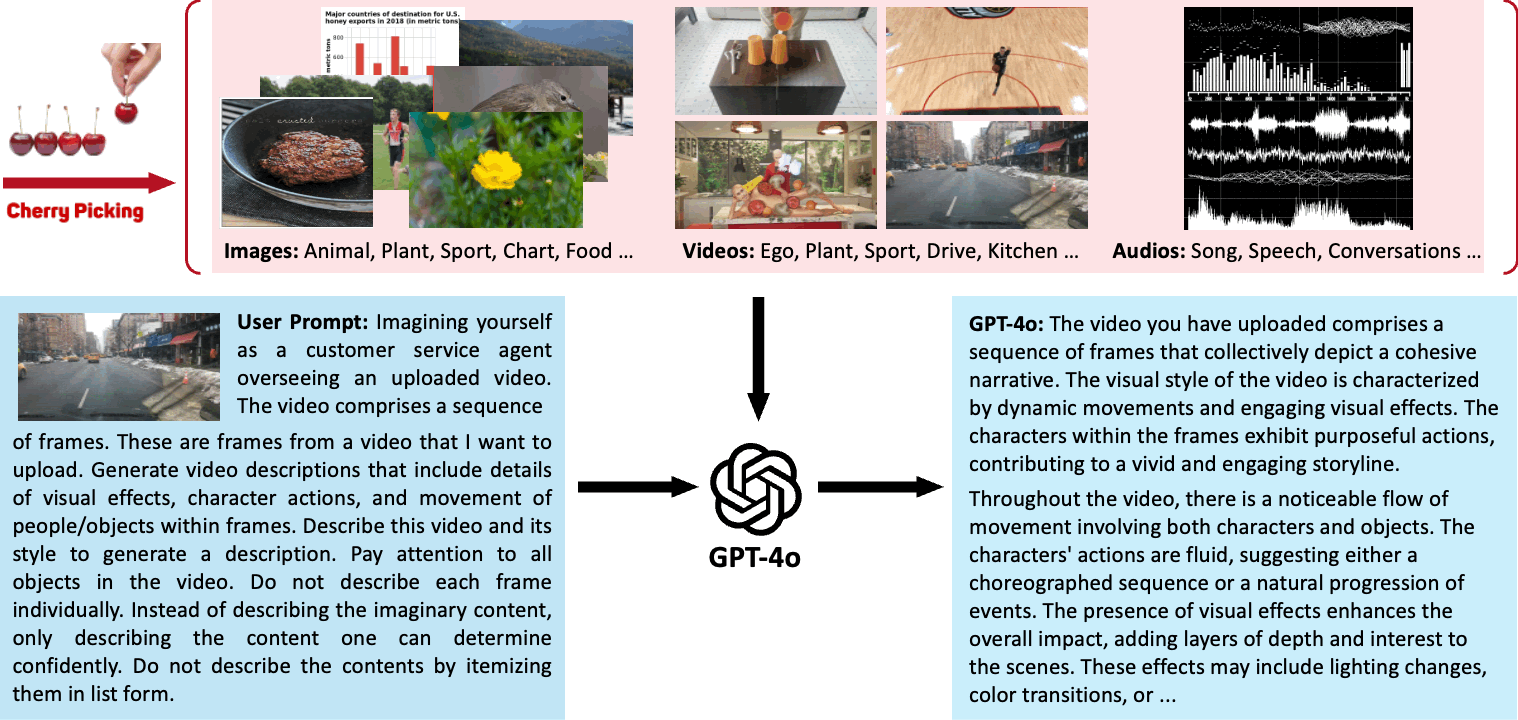
We demonstrate our process of using GPT-4o to generate highly descriptive captions for images, videos, and audio based on specific user prompts in the following section. We first filter and screen a large number of images, videos, and audio to obtain high-quality data sources from various aspects.
Then, we customize prompts and utilize GPT-4o's powerful multimodal capabilities to annotate them with captions, ultimately resulting in a high-quality multimodal dataset.
| Domain | Source Document | Caption Document | Description |
|---|---|---|---|
| Image | images.zip | image_conversations |
The images.zip file contains 50k images. The image_conversations file includes a JSONL file annotated with captions by GPT-4o. Each element in the JSONL file is formatted as follows:
{
"image": "image_id.jpg",
"width": ,
"height": ,
"conversations": [
{"from": "human", "value": "<image>\n+prompt"},
{"from": "gpt", "value": "caption"}
]
}
|
| Video | videos.zip | video_conversations |
The videos.zip file contains 2k videos. The video_conversations file includes a JSONL file annotated with captions by GPT-4o. Each element in the JSONL file is formatted as follows:
{
"video": "video_id.mp4",
"width": ,
"height": ,
"conversations": [
{"from": "human", "value": "<video>\n+prompt"},
{"from": "gpt", "value": "caption"}
]
}
|
✔️ 50k Image caption generated by GPT-4o
✔️ 2k Video caption generated by GPT-4o
[TBD] Voice caption generated by GPT-4o
[TBD] More image/video caption/QA generated by GPT-4o
If you find our work helpful for your research, please consider giving a citation 📃
@misc{cui2025comprehensive,
author = {Erfei Cui and Yinan He and Zheng Ma and Zhe Chen and Hao Tian and Weiyun Wang and Kunchang Li and Yi Wang and Wenhai Wang and Xizhou Zhu and Lewei Lu and Tong Lu and Yali Wang and Limin Wang and Yu Qiao and Jifeng Dai},
title = {ShareGPT-4o: Comprehensive Multimodal Annotations With GPT-4o},
year = {2024},
url = {https://sharegpt4o.github.io/},
}
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@misc{wang2024internvid,
title={InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation},
author={Yi Wang and Yinan He and Yizhuo Li and Kunchang Li and Jiashuo Yu and Xin Ma and Xinhao Li and Guo Chen and Xinyuan Chen and Yaohui Wang and Conghui He and Ping Luo and Ziwei Liu and Yali Wang and Limin Wang and Yu Qiao},
year={2024},
eprint={2307.06942},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{wang2024internvideo2,
title={InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding},
author={Wang, Yi and Li, Kunchang and Li, Xinhao and Yu, Jiashuo and He, Yinan and Chen, Guo and Pei, Baoqi and Zheng, Rongkun and Xu, Jilan and Wang, Zun and Shi, Yansong and Jiang, Tianxiang and Li, Songze and Zhang, Hongjie and Huang, Yifei and Qiao, Yu and Wang, Yali and Wang, Limin},
journal={arXiv preprint arXiv:2403.15377},
year={2024}
}
@misc{li2023mvbench,
title={MVBench: A Comprehensive Multi-modal Video Understanding Benchmark},
author={Kunchang Li and Yali Wang and Yinan He and Yizhuo Li and Yi Wang and Yi Liu and Zun Wang and Jilan Xu and Guo Chen and Ping Luo and Limin Wang and Yu Qiao},
year={2023},
eprint={2311.17005},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
This website is adapted from Nerfies and LLaVA, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.